Welches technische Problem muss also gelöst werden?
Große Sprachmodelle nutzen künstliche neuronale Netze, um das jeweils nächste Wort vorherzusagen.
Wie die Ausgabeseite aussieht, können wir uns gut vorstellen: Erinnern wir uns noch einmal an die Tier- und die Zeichenerkennung. Dort hat es für jedes Tier bzw. jedes Zeichen, das erkannt werden könnte, ein Neuron in der Ausgabeschicht gegeben. Die Aktivierung eines jeden dieser Neuronen steht für die Wahrscheinlichkeit, dass es sich um dieses Tier bzw. dieses Zeichen handelt: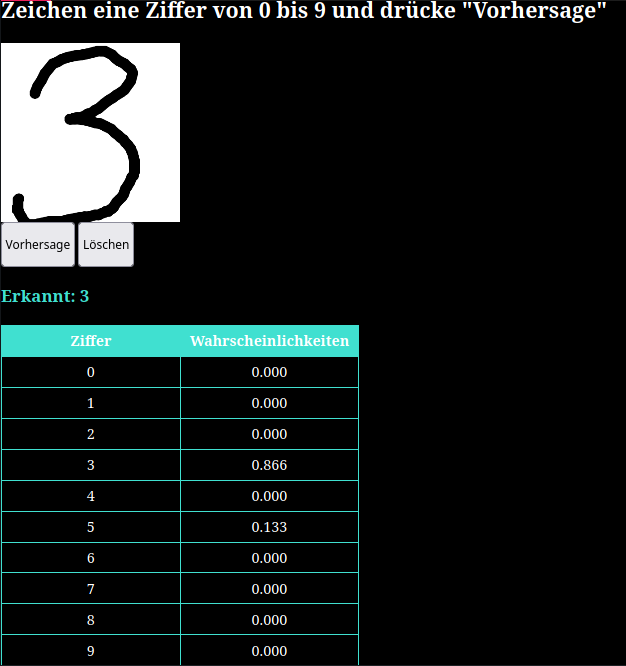

Genau so gibt es bei einem LLM auf der Ausgabeseite für jedes Wort des Wortschatzes ein Neuron. Angenommen, unser Wortschatz umfasst nur 10 Wörter (in Wahrheit sind es viel mehr...), dann könnte unser Netz auf der Ausgabeseite so aussehen:
| Wahrscheinlichkeit für Wort 1 | 0.011 |
| Wahrscheinlichkeit für Wort 2 | 0.253 |
| Wahrscheinlichkeit für Wort 3 | 0.065 |
| Wahrscheinlichkeit für Wort 4 | 0.001 |
| Wahrscheinlichkeit für Wort 5 | 0.034 |
| Wahrscheinlichkeit für Wort 6 | 0.126 |
| Wahrscheinlichkeit für Wort 7 | 0.433 |
| Wahrscheinlichkeit für Wort 8 | 0.201 |
| Wahrscheinlichkeit für Wort 9 | 0.004 |
| Wahrscheinlichkeit für Wort 10 | 0.001 |
Wir können uns auch vorstellen, dass ein künstliches neuronales Netz mit seinen Millionen und Millarden von Gewichten irgendwie lernt, diese Wahrscheinlichkeiten sinnvoll zu berechnen.
Die entscheidende Frage ist aber: Wie können wir (zum Training und für die Berechnung) Wortfolgen in das neuronale Netz auf der Eingabeseite einspeisen, und zwar auf eine Art und Weise, die Wortfolgen unterschiedlicher Länge erlaubt und Ähnlichkeiten beim Sinn und der Bedeutung erkennt?


